


Вход на хостинг
IT-новости
20.04.2016 iPhone 2017 года поместят в водонепроницаемый корпус из стекла
Линейка iPhone в новом году серьезно поменяется. В этом уверен аналитический исследователь Мин Чи Ку......

30.07.2015 Ищем уникальный контент для сайта
Ищем уникальный контент для сайта Без уникального контента Ваш сайт обречен на то, что его страницы......
11.05.2015 Распространённые ошибки разработчиков сайтов
Не секрет, что в сети Интернет насчитывается миллионы сайтов, и каждый день появляются тысячси новых......
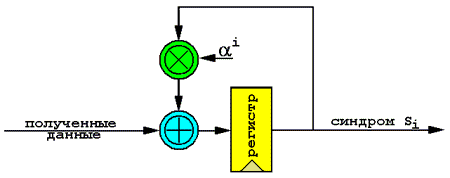
Рисунок 4. Блок-схема цепи вычисления синдрома
Вычисление синдрома ошибки происходит итеративно, так что вычисление результирующего полинома (также называемого ответом от английского «answer») завершается непосредственно в момент прохождения последнего символа четности через фильтр. Всего требуется 2t циклов «прогона» декодируемых данных через фильтр, – по одному прогону на каждый символ результирующего полинома.
Пример простой программной реализации синдромного декодера содержится в листинге 2, и он намного нагляднее его словесного описания.
Полином локатора ошибки
Полученный синдром описывает конфигурацию ошибки, но еще не говорит нам, какие именно символы полученного сообщения были искажены. Действительно, степень синдромного полинома, равная 2t, много меньше степени полинома сообщения, равной n, и между их коэффициентами нет прямого соответствия. Полином, коэффициенты которого напрямую соответствуют коэффициентам искаженных символов, называется полиномом локатора ошибки и по общепринятому соглашению обозначается греческой буквой L (лямбда).
Если количество искаженных символов не превышает t, между синдромом и локатором ошибки существует следующее однозначное соответствие, выражаемое следующей формулой НОД[xn-1, E(x)] = L(x), и вычисление локатора сводится к задаче нахождения наименьшего общего делителя, успешно решенной еще Евклидом и элементарно реализуемой как на программном, так и на аппаратном уровне. Правда, за простоту реализации нам приходится расплачиваться производительностью, точнее непроизводительностью данного алгоритма, и на практике обычно применяют более эффективный, но и более сложный для понимания алгоритм Берлекэмпа-Месси (Berlekamp-Massy), подробно описанный Кнутом во втором томе «Искусства программирования» (см. также «Теория и практика кодов, контролирующих ошибки» Блейхута) и сводящийся к задаче построения цепи регистров сдвига с линейной обратной связью и по сути своей являющегося разновидностью авторегрессионого фильтра, множители в векторах которого и задают полином L.
Декодер, построенный по такому алгоритму, требует не более 3t операций умножения в каждой из итерации, количество которых не превышает 2t. Таким образом, решение поставленной задачи укладывается всего в 6t2 операций умножения. Фактически поиск локатора сводится к решению системы из 2t уравнений – по одному уравнению на каждый символ синдрома – c t неизвестными. Неизвестные члены и есть позиции искаженных символов в кодовом слове v. Легко видеть, если количество ошибок превышает t, система уравнений становится неразрешима и восстановить разрушенную информацию в этом случае не представляется возможным.
Блок-схема алгоритма Берлекэмпа-Месси приведена на рис. 5, а его законченная программа реализация содержится в листинге 2.
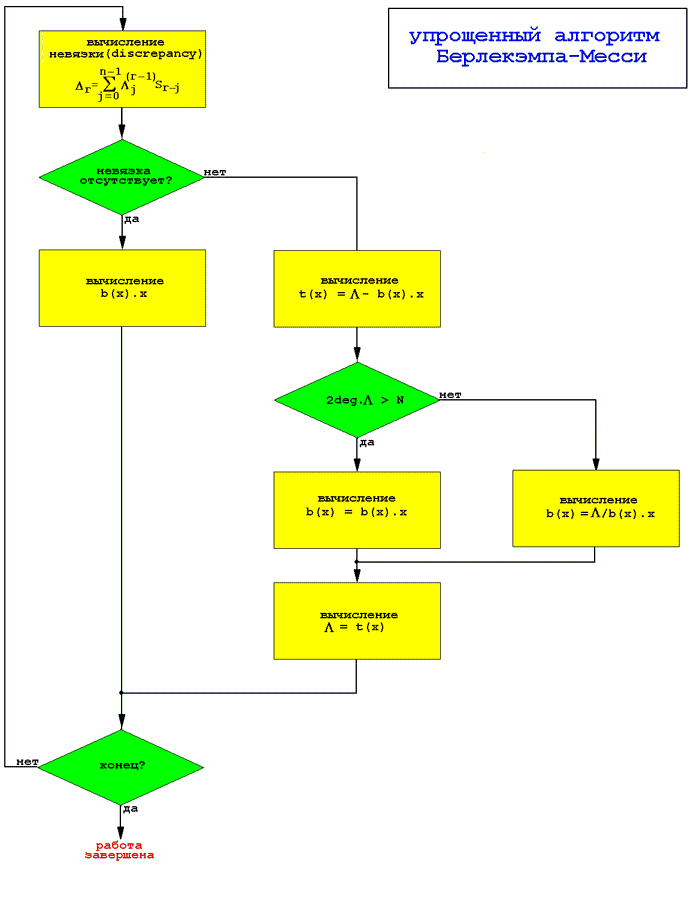
Рисунок 5. Структурная схема алгоритма Берлекэмпа-Месси
Корни полинома
Коль скоро полином локатора ошибки нам известен, его корни определяют местоположение искаженных символов в принятом кодовом слове. Остается эти корни найти. Чаще всего для этого используется процедура Ченя (Chien search), аналогичная по своей природе обратному преобразованию Фурье и фактически сводящаяся к тупому перебору (brute force, exhaustive search) всех возможных вариантов. Все 2m возможных символов один за другим подставляются в полином локатора в порядке социалистической очереди и затем выполняется расчет полинома. Если результат обращается в ноль – считается, что искомые корни найдены.
Восстановление данных
Итак, мы знаем, какие символы кодового слова искажены, но пока еще не готовы ответить на вопрос: как именно они искажены. Используя полином синдрома и корни полинома локатора, мы можем определить характер разрушений каждого из искаженных символов. Обычно для этой цели используется алгоритм Форни (Forney), состоящий из двух стадий: сначала путем свертки полинома синдрома полиномом локатора L мы получаем некоторый промежуточный полином, условно обозначаемый греческой буквой W. Затем на основе W-полинома вычисляется нулевая позиция ошибки (zero error location), которая в свою очередь делится на производную от L-полинома. В результате получается битовая маска, каждый из установленных битов которой соответствует искаженному биту и для восстановления кодового слова в исходный вид все искаженные биты должны быть инвертированы, что осуществляется посредством логической операции XOR.
На этом процедура декодирования принятого кодового слова считается законченной. Остается отсечь n – k символов четности, и полученное информационное слово готово к употреблению.
Исходный текст декодера
Ниже приводится исходный текст полноценного декодера Рида-Соломона, снабженный минимально разумным количеством комментариев. К сожалению, в рамках журнальной статьи подробное комментирование кода декодера невозможно, поскольку потребовало бы очень много места.
ООО Дельта-Технология ©2007 - 2023 год
Нижний Новгород, ул. Дальняя, 17А.
