


Вход на хостинг
IT-новости
20.04.2016 iPhone 2017 года поместят в водонепроницаемый корпус из стекла
Линейка iPhone в новом году серьезно поменяется. В этом уверен аналитический исследователь Мин Чи Ку......

30.07.2015 Ищем уникальный контент для сайта
Ищем уникальный контент для сайта Без уникального контента Ваш сайт обречен на то, что его страницы......
11.05.2015 Распространённые ошибки разработчиков сайтов
Не секрет, что в сети Интернет насчитывается миллионы сайтов, и каждый день появляются тысячси новых......
Оптимизация сортировки в Perl
Алексей Мичурин
В пилотном номере журнала «Системный администратор» была опубликована статья Даниила Алиевского – «Эффективное использование памяти в Perl при работе с большими строками». Тогда-то у меня и возникла мысль написать статью об эффективном использовании времени в Perl, то есть об оптимизации, направленной на увеличение быстродействия.
При работе с массивами (списками) сортировка является, наверное, наиболее частой операцией. Я не беру в расчёт операции, отвечающие фактически за создание списков: присоединение и удаление элементов, объединение массивов, срез и тому подобные; мы займёмся преобразованием уже созданных списков. Мало кто поспорит с тем, что процедура сортировки является весьма ресурсоёмкой. Можно ли снизить нагрузку на систему, не вмешиваясь в сам алгоритм сортировки?
В этой статье я хотел бы рассказать о путях оптимизации сортировки в Perl, но думаю, что изложенные здесь приёмы могут быть полезны и для программистов на других языках. Особенно, когда речь идёт о языках высокого уровня, где уже существуют встроенные функции сортировки, и вам не надо писать алгоритм сортировки самостоятельно, но и вмешаться в него вы уже не можете. Я не смогу написать здесь учебник по Perl, но я постараюсь сделать статью максимально понятной и для людей, не знакомых с Perl.
Давайте сперва изучим особенности алгоритма сортировки, вернее особенности её реализации в Perl 5.6. Я не буду здесь рассматривать саму реализацию. Она достаточно сложна и вместе с тем отлично прокомментирована в исходных кодах Perl. Если вас интересует этот вопрос, просто почитайте исходные коды. Итак, приступим.
Оценка производительности сортировки в Perl
В качестве критерия производительности я выбрал величину, равную отношению: в числителе – количество сравнений, необходимое для выполнения сортировки, в знаменателе – количество элементов в сортируемом списке. То есть величину, показывающую, сколько сравнений приходится в среднем на один элемент списка. Естественно, эта величина зависит и от размера массива, и от меры его начальной упорядоченности.
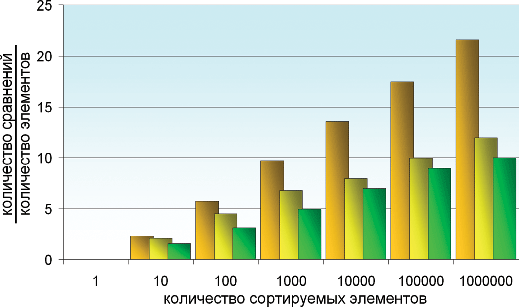
Рисунок 1. Результаты тестов производительности встроенной процедуры сортировки языка Perl для изначально упорядоченных массивов (упор.),
обратноупорядоченных массивов (обр.) и не упорядоченных массивов (случ.) различной длины.
На приведённой диаграмме показаны результаты тестов, проведённых на разных массивах. Тестировались три рода массивов: упорядоченный (в результате сортировки массив не менялся), обратноупорядоченный (в результате сортировки массив перестраивался в обратном порядке) и массив случайных величин (для этого случая на диаграмме показаны средние значения).
Как видите, наименее ресурсоёмкой оказалась сортировка уже отсортированного массива, чего, наверное, и следовало ожидать. Менее тривиальный результат состоит в том, что для сортировки обратноупорядоченного массива требуется не намного больше актов сравнения, чем для упорядоченного. И самой ресурсоёмкой оказывается сортировка «случайного» (неупорядоченного) списка.
ООО Дельта-Технология ©2007 - 2023 год
Нижний Новгород, ул. Дальняя, 17А.
